
While Kubernetes’ ability to streamline application deployment and management across diverse environments has made it an indispensable tool for modern development teams, the dynamic nature of Kubernetes workloads can lead to cloud “sticker shock.” These unexpected cost surges pose significant challenges for companies seeking to continue their cloud-native and application modernization initiatives.
Navigating this complex landscape becomes crucial for striking a balance between innovation and financial prudence. To achieve this balance, continuous and automatic resource optimization is a non-negotiable requirement in Kubernetes environments.
This is the first part of a tutorial blog series where we’ll describe some of the key reasons why Kubernetes is not natively designed to be resource-efficient, the financial implications of this inefficiency, and show you how to implement a suite of solutions to achieve resource efficiency at many levels within your Kubernetes environment.
It’s pretty well understood that Kubernetes can be incredibly expensive to run, particularly at scale. Viewing the problem through the lens of resource management, we must begin with the fact that Kubernetes abstracts away much of the underlying infrastructure, allowing developers to focus squarely on their applications (in Kubernetes parlance: workloads).
These workloads are submitted to Kubernetes which then makes a determination as to whether or not there are suitable nodes that can host the new workload(s).
From a resource perspective, if your workload is configured to request 4 CPUs and 8 gigabytes of memory, and there are no available nodes with resource capacity, then a well-architected Kubernetes environment will employ a node autoscaler (like Cluster Autoscaler) to provision a new node and add the requested resources.
spec:
containers:
resources:
requests:
cpu: "4"
memory: 8GiFigure 1: Your workload spec is set to request 4 CPUs and 8 Gigabytes of memory
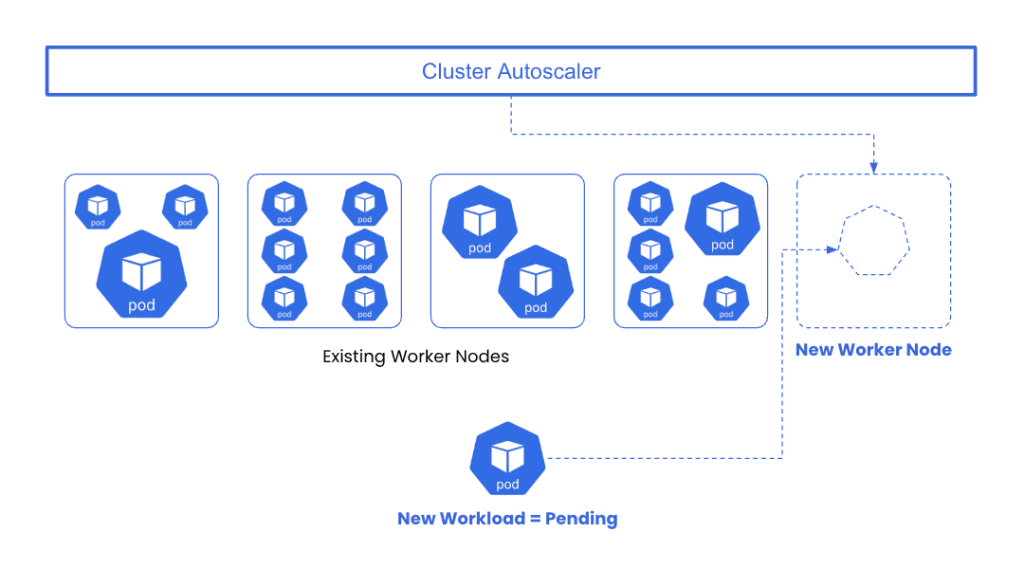
Congratulations! You have a cluster that automatically provisions nodes/resources to accommodate new workload resource requirements. The problem is that Kubernetes is poorly equipped to understand the difference between resource requests and resource usage – and subsequently does very little to address over-provisioning – a primary driver of runaway costs.
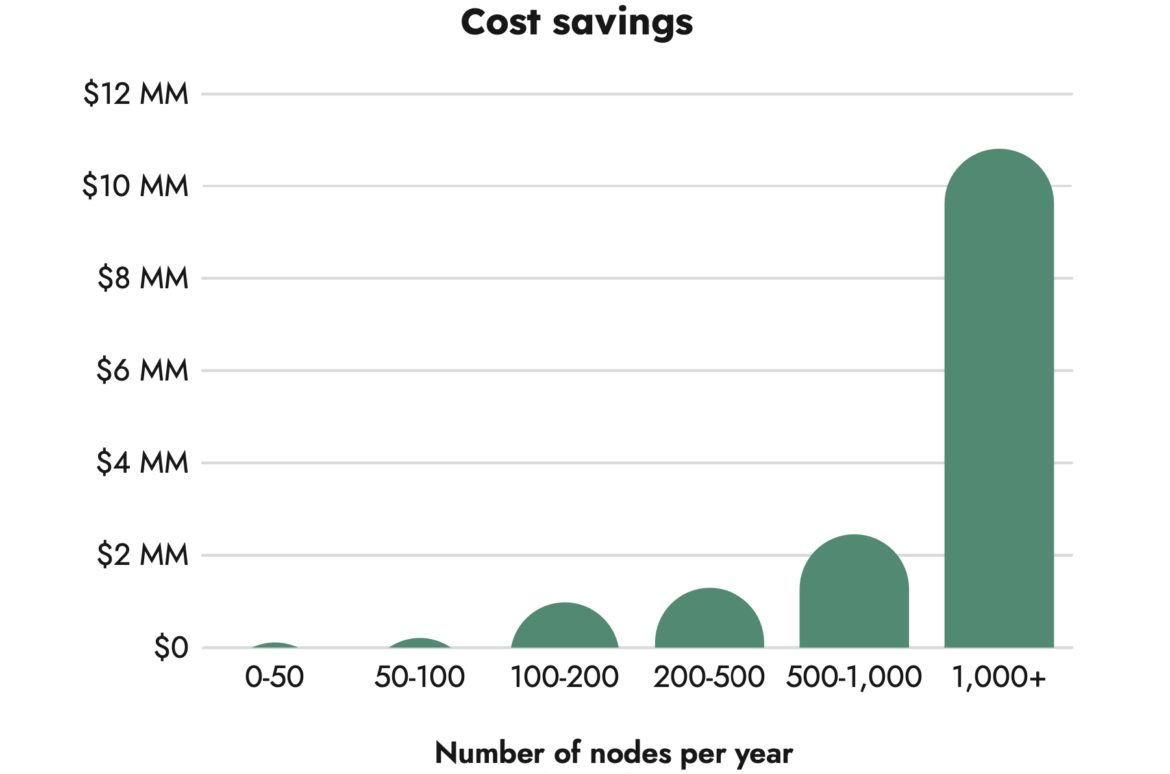
A recent survey suggests that an average of 69% of allocated CPU and 18% of allocated memory goes unused – both numbers representing millions of dollars in wasted resources per year for larger organizations.[/vc_column_text]

.
As dynamic and elastic as Kubernetes is, it still behaves according to rigid sets of rules which are often set once and forgotten, without a thought towards right-sizing in the future. Without sophisticated tooling and automation, resource over-provisioning and poor cost performance is unavoidable.
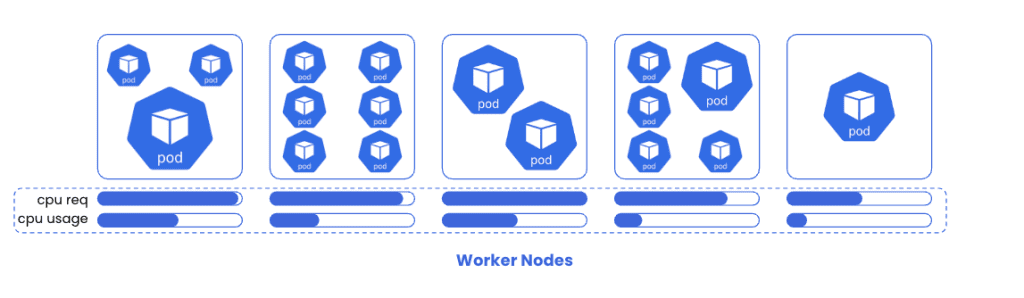
You can think of this Kubernetes resource/cost paradox much like walking into an empty restaurant where despite the plethora of empty tables, the host/ess insists that all of the tables are booked and that you and your party cannot be seated.
Alas if this restaurant was anything like Kubernetes, the hostess would instantaneously hire a construction crew to extend the restaurant, add chairs and tables, and then seat you as quickly as possible.

As cost-prohibitive as this model might seem with regard to running a restaurant, it is every bit as absurd when it comes to running Kubernetes and managing its resources.
If the goal is to avoid the unwieldy resource over-provisioning and runaway costs described above, what would an ideal solution look like at a high-level?
Well, first, we’ll need to implement a system which provisions and deprovisions nodes more intelligently and efficiently than the traditional Cluster Autoscaler. It should make better decisions around node size, taking into account bin-packing efficiency based on workload resource requests, and it should quickly scale out and back in to ensure we’re limiting our exposure to expensive and idle compute capacity.
Second, we’ll need to address the challenge of right-sizing the workload resource requests based on their actual usage, not some arbitrary value that was set once and forgotten about. An intelligent node autoscaler will base its node sizing decisions on aggregate resource requests of pending workloads – so it’s in our best interest to right-size those requests so that the node autoscaler is as efficient as possible.
And lastly, we’ll want to drive these behaviors automatically – so that developers and platform engineers can spend as little time as possible making sure these cost optimizations are happening on a continuous basis. Implementing a policy engine to enforce these results is a must.
The good news within this cost optimization paradigm is that there are a number of solutions that address resource efficiency at every level, thereby optimizing and continuously keeping a lid on those pesky Kubernetes costs.
Over the next few posts, we’ll focus on two solutions we believe are the most effective in working together to solve the Kubernetes cost optimization problem: Karpenter and StormForge Optimize Live.
To address the challenge of node sizing and autoscaling – Karpenter is an open-source tool designed to efficiently manage and optimize node provisioning for Kubernetes clusters. It improves upon the Kubernetes-native cluster autoscaler, by providing intelligent node autoscaling and opportunistic workload consolidation in an effort to minimize the total number of worker nodes needed to support running workloads.
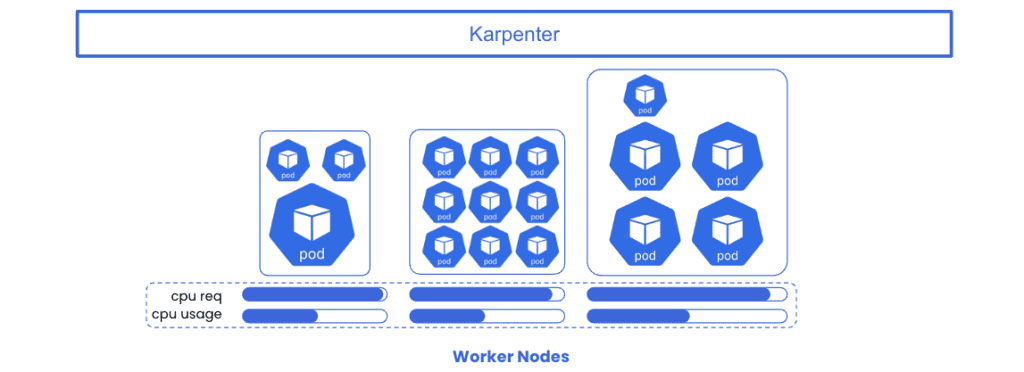
To address the need to right-size your workloads – StormForge Optimize Live significantly enhances the effect of Karpenter by continuously analyzing real-time data on workload resource utilization, generating precise recommendations for right-sizing resource requests, and seamlessly implementing optimal workload configurations. When used together, Karpenter and Optimize Live autonomously address both sides of the resource-cost-optimization paradigm, maximizing resource efficiency and ROI for investment in Kubernetes while reducing the burden on platform operations teams.
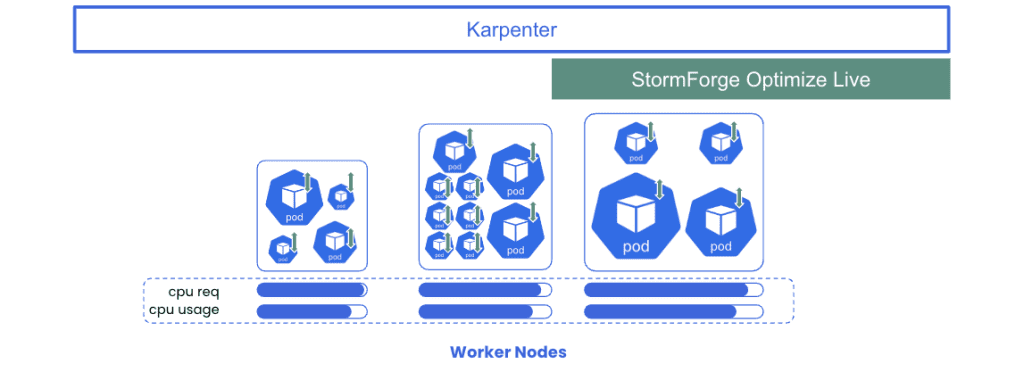
By implementing these solutions together, you can ensure that your Kubernetes platform is “optimized by default” at the workload as well as the node level – all while mitigating time consuming and inconsistent tuning exercises.
Read the next blog in this series to dive a little deeper into Karpenter, provide references for configuring its node provisioners, and show examples of how Karpenter can drive down node resource costs in an active Kubernetes environment.
Then in part 3 of this series, you can learn how to rightsize workloads by implementing and managing Optimize Live.
We use cookies to provide you with a better website experience and to analyze the site traffic. Please read our "privacy policy" for more information.


