Blog
Kubernetes Management: Action(able) is Everything. If You See Something, Say Something.
By Ram Narayanan | Jun 21, 2022

Blog
By Ram Narayanan | Jun 21, 2022
Whether you think the hype is justified or not, Kubernetes is now front and center – the star if you will – in the arena of enterprise application development and deployment. The containerization of tens, hundreds, or thousands of applications and microservices undoubtedly facilitates speed, scale and flexibility – until it doesn’t. Your reaction to that might be “huh??” But if you’ve started deploying and managing enterprise Kubernetes environments, your reaction is probably more like “uh-huh”.
If you have some experience with containers, you know that Kubernetes really is a big deal. It grabs the baton from virtualization in the race for operational efficiency and crosses over to a different event altogether – from running or cycling to something more akin to NASCAR. Yeah, race cars sure do go fast, but the general consensus is that their combustion engines also consume (waste) a lot more fuel than runners or cyclists do. And they have a lot of parts – parts that need monitoring, tuning and replacement…not by just one person, but by a team of people.
Hey, aren’t Kubernetes architectures doing something comparable? You have plenty of horsepower now – to deploy your containers fast and put them practically wherever you want. But how’s the resource and management efficiency part of the story going? If you think it could be better, then you’re in good company. Unfortunately that’s not where you want to be. Here are some stats to ponder:
A 2021 D2iQ study found that Kubernetes is a source of pain or complexity for 94% of organizations. In a recent Circonus survey, 58% of Kubernetes operators said that managing their Kubernetes infrastructure and ecosystem is a top challenge. And, according to Red Hat, 75% of users say that operational complexity is the biggest impediment to using Kubernetes in production. Where’s the biggest pain? Well, it turns out that not all enterprise Kubernetes management activities are created equal. The easy steps really are fairly easy, but the hard ones are nearly impossible to successfully achieve through manual efforts.
Now this could turn into a pretty lengthy write-up if we want to cover all Kubernetes management activities in detail. So let’s just take a bird’s eye view of a few management options – what each one offers, and where it might fall short of our objective…which is to simplify and automate as much of the time-consuming aspects of enterprise Kubernetes management as possible.
Managed cloud services. If your organization has decided to deploy a cloud-native Kubernetes architecture you might consider a managed service offering – for example Amazon (EKS), Azure (AKS) or Google (GKE). No matter which one you choose, you can access some pretty advanced capabilities such as automated provisioning, patching, upgrades, cluster monitoring and more. The downside – as with any cloud service – is that you’re kind of locked into a particular cloud platform with their specific APIs, etc.
Kubernetes management platforms. Maybe your team wants to deploy Kubernetes on-premises or in a hybrid cloud – and doesn’t want to be locked into a specific cloud vendor’s environment or business model. Some organizations go with a Kubernetes management platform to meet their container orchestration needs. These are usually specific Kubernetes distributions that bundle the software (open source code) with additional tools that simplify installation, integration, monitoring, security and more. Examples include VMware Tanzu, SUSE Rancher, Red Hat OpenShift and Mirantis Kubernetes Engine. There are several more. Although these solutions don’t lock you into a cloud platform, they essentially tie you to a management platform. Despite the flexibility that containers offer, it may not be that easy to migrate from one management platform to another or to an open-source Kubernetes distribution once you’ve settled on one of them.
Regardless of which of the above options you select, you’re going to have some nice benefits when it comes to Kubernetes lifecycle management. You’ll be able to create, deploy and upgrade container-based environments fairly easily. And you can even scale, observe and optimize them – to some degree at least. What else is required or missing?
As you might expect, a big part of enterprise Kubernetes management is resource management. That’s to make sure your apps are behaving and performing at the level you want – if possible without your Kubernetes teams spending all their time trying to make that happen. So you first need a really good way to figure out what’s going on across all of your Kubernetes architecture and infrastructure assets. Where are there existing or potential performance bottlenecks? Where are there capacity issues? What resources are being over- or under-consumed?
Just about all infrastructure technologies – storage, servers, network switches, VMs – and the applications they support, have monitoring capabilities. But how do you correlate all of the alerts and information that you’re getting in Kubernetes environments, which are becoming increasingly complex and dynamic? How do you know which of the hundreds of alerts being generated in your Kubernetes environment are important and which ones are just “noise”? Do you know which component(s) represent the buttons and levers that can actually affect your application SLAs and SLOs? The challenges of discovering, tracking, evaluating and troubleshooting problems become even more pronounced in multi-cloud scenarios, where a single cloud vendor or Kubernetes management platform might not have the reach to connect all the dots across a dispersed infrastructure.
This is where observability tools or platforms come into the picture. Prometheus, Datadog, Dynatrace and New Relic are some examples of such solutions. They can centrally monitor metrics, events and application traces across the entire infrastructure and software stack – something that Kubernetes cloud services and management platforms don’t do very well. Observability is a key aspect of Kubernetes management because it ultimately helps you understand the behavior of various components in the environment with a holistic, big picture view that ties aggregate component behavior back to quality of service and the user experience. This adds considerable value and differentiation beyond the capabilities of the Kubernetes management solutions mentioned above.
Where do we go from here? Well, it’s great to have the monitoring and observability metrics and tracing that help you pinpoint the location of existing or potential problems. But what resource management actions are required to resolve the issue – or to make sure it doesn’t happen again – or to avoid it from happening in the first place?
Because Kubernetes resource management is so complex, most organizations have a really tough time maintaining efficiency and optimizing performance for their containerized apps – especially at scale. There are many interrelated configuration variables that need to be tuned. And optimization, if it does occur, is the result of a reactive and manual trial-and-error process. Why is this still so difficult and complicated? Let’s take a closer look at the problem.
When you deploy a containerized app, there are several configuration decisions you have to make – memory and CPU requests and limits, replicas, application-specific settings such as JVM heap size and garbage collection – the list goes on and on. Let’s say you have 20 variables that you’re observing in order to optimize performance, reliability, cost-efficiency or whatever. When you try to optimize each variable simultaneously to arrive at the “best” configuration for that workload, the number of possible combinations can run into the billions. When you consider the number of containers you’ve got, plus the fact that all these parameters are interrelated, the number of combinations is essentially infinite – and it’s probably not a good idea to address that problem manually.
In the meantime, wrong choices lead to suboptimal configurations, which can cause application failures, poor performance, delayed development and product release cycles, and almost certainly a less-than-satisfactory user experience. And because it’s so hard to figure out how to optimize the environment, Kubernetes teams often (usually) just take the path of least resistance (and highest cost) by over-provisioning cloud resources for their containers. This last point is probably the one that FinOps teams are most concerned with. A recent StormForge study revealed that almost 50% of cloud spend is wasted.
That’s where an automated Kubernetes resource management and optimization solution like StormForge comes in. StormForge leverages the observability data you’re already collecting – and takes it to the next level with actionable intelligence. Observability tells you what issues you’ve got and where they’re located. Actionability tells you what you can do about it – in the most optimal way. You get actionable insights – and recommendations – to keep your production environment running efficiently. And did I mention that it’s automated? If you want you can let go of the wheel and let StormForge take action autonomously on its own insights and recommendations. Your team can save countless hours – days, weeks, months – of administrative effort and expense.
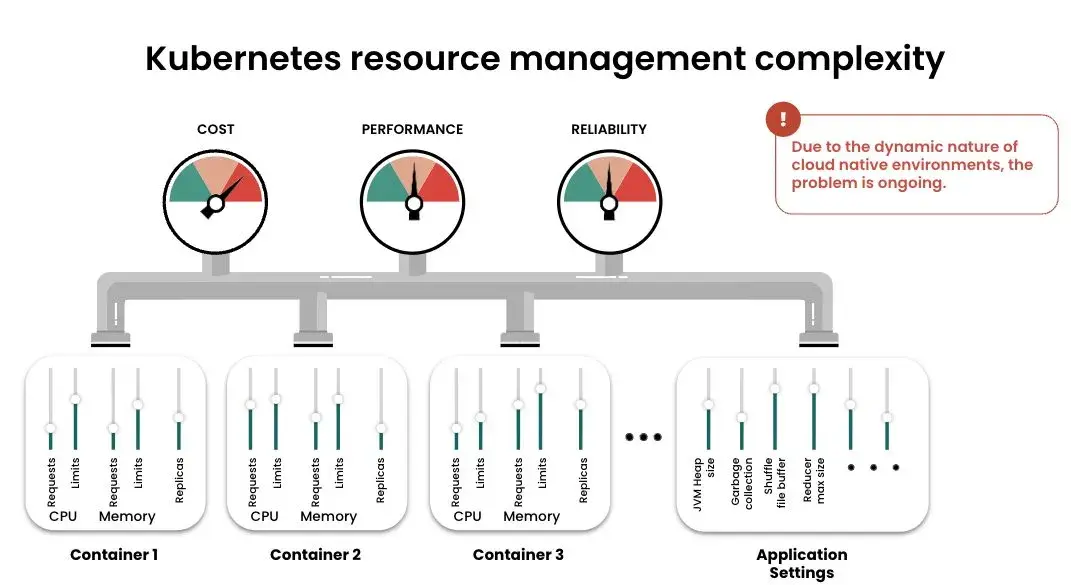
Resource optimization is among the most challenging aspects of enterprise Kubernetes management – yet once achieved, it’s among the most rewarding – whether the objective is performance or cost-related. In fact, StormForge is the only solution that can optimize for multiple competing objectives such as performance and cost. That makes it easy to see the trade-offs and make the right decisions for your business. StormForge is also the only solution that uses patent-pending machine learning for both pre-production scenario analysis and production optimization based on observability data. This ensures your Kubernetes environment is always operating at peak efficiency – minimizing costs and resource usage while delivering the required performance. As shown in Figure 2, StormForge customers are seeing more than 50% improvements in both performance and cost-savings.
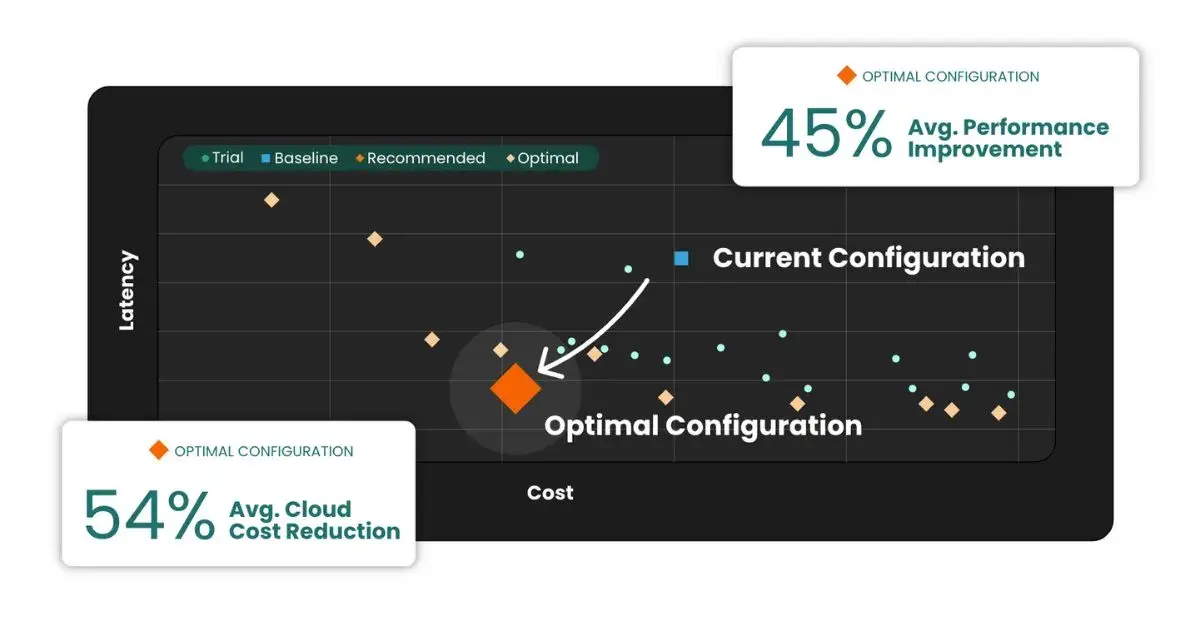
StormForge turns visibility and observability into actionable insights for fast, simplified configuration and optimization of production applications. And non-production scenario planning and rapid experimentation gives you the deep application insights that help drive architectural improvements. For example, you may find it’s better to run more replicas with smaller instances versus fewer but larger replicas. These intelligent, automated recommendations improve your resource efficiency and get your team out of the Kubernetes configuration, tuning, and troubleshooting business – so they can focus on innovation and other higher-value objectives.
Another important aspect of Kubernetes resource management is scaling – intelligent, automated scaling to be more specific. Studies show that nearly 40% of organizations experience problems scaling their Kubernetes environments. StormForge machine learning analyzes actual usage and historical trends to accurately predict future resource needs – whether you’re managing tens of containers or tens of thousands. ML-based recommendations have proven to align very closely with actual usage, eliminating resource slack and reducing the risk of CPU throttling and out-of-memory errors.
StormForge is designed to fit into your cloud-native ecosystem. It’s an open platform that works with any and all of the technologies we’ve discussed so far. That means any cloud, any Kubernetes management platform, any CI/CD tool, any monitoring / observability solution and any codebase.

Kubernetes management refers to the set of activities required to effectively operate a Kubernetes container-based application environment. The architecture for such an environment utilizes containers, nodes, pods and other infrastructure components. Kubernetes open source distributions include ways to deploy, scale and administer these environments. However the deployment of numerous containers and associated resources – CPUs, memory, and more – with such a high degree of application abstraction results in a complex infrastructure; one that is difficult to optimize for performance and end-user experience without wasting cloud resources and IT administrative effort.
Several aspects of Kubernetes management can be simplified by using a Kubernetes cloud service (e.g., from Amazon, Azure, Google) or a Kubernetes management platform (OpenShift, Tanzu, Rancher, etc). These solutions can simplify or automate provisioning, patching, upgrades, cluster monitoring, integration, and security.
Observability platforms augment these management solutions by centrally monitoring the behavior of infrastructure components and applications across the entire infrastructure and software stack. The result is a holistic, big picture view that ties aggregate component behavior to its impact on quality of service and the user experience.
An automated Kubernetes resource management and optimization solution like StormForge leverages observability data and takes it to the next level with intelligent action. Actionable ML-driven insights and recommendations optimize Kubernetes resources for up to thousands of containers, keeping pre-production and production environments running efficiently and optimizing performance at scale, without over-provisioning cloud resources. StormForge can also take action autonomously, saving days, weeks, even months of administrative effort and expense.
Kubernetes is considered a container orchestration platform. It may also be useful to think of it as an open-source framework. The last few words help reiterate the idea that Kubernetes is a work-in-progress, with regular, community-driven updates. And because it is a work-in-progress, it is, by definition, incomplete. It is a powerful platform for accelerating application development, deployment and portability at scale. But it is far from being a standalone or “out of box” solution.
“Enterprise Kubernetes” is a term frequently used by Kubernetes management platform vendors. It implies that their solutions include additional capabilities, on top of Kubernetes source code, that make them enterprise-ready. These capabilities include things like security hardening, multi-tenancy, integration with existing technologies, and simplified or automated patching and upgrades. As Kubernetes ecosystems mature, it is reasonable – even essential – to consider other elements among the requirements for an “enterprise Kubernetes solution”. This includes package and configuration management, platform monitoring and observability, and intelligent resource optimization.
Kubernetes is an open-source platform for managing container-based workloads and services. It is not a configuration management tool, but it does offer ways to manage resources (configurations) for a Kubernetes cluster. It is possible to manage cluster configuration parameters via the Kubernetes API, but most teams use higher-level tools to interact with the cluster – YAML files, for example. There are, however, many configuration parameters and settings to consider in a containerized environment. Therefore, using YAML files can quickly become a cumbersome process that’s potentially riddled with errors when it becomes necessary to customize, modify or share configurations. Many organizations use other tools such as package managers to simplify configuration management at scale. The most popular one is Helm.
Kubernetes environments are complex and require a great deal of management. Ironically, the primary reason is because one of the objectives of Kubernetes is to keep applications and application management as simple as possible. Many activities previously managed by applications are now handled by the Kubernetes framework. This includes security, redundancy, logging, error-handling and scaling. The advent of containerized, lightweight apps greatly reduces and simplifies application code, which enables apps to be created, deployed and modified easily for faster development and release cycles.
Simplifying the apps, however, makes application infrastructure management more difficult because the Kubernetes ecosystem now has to handle all these tasks that were previously managed by the application. This includes coordinating and automating tasks when possible, and managing configuration resources for each application. This is particularly challenging due to the high level of abstraction between application and infrastructure layers in containerized environments.
Intelligently optimizing resources and solving for performance, scalability and cost-efficiency trade-offs is another important and difficult problem that none of the Kubernetes management solutions have successfully tackled. Resource optimization is an essential aspect of Kubernetes management that StormForge delivers with unique ML-based technology.
We use cookies to provide you with a better website experience and to analyze the site traffic. Please read our "privacy policy" for more information.


