One of the challenges when scaling JVM-based applications in Kubernetes using a Horizontal Pod Autoscaler (HPA) is the potential for thrashing due to the CPU burst that occurs during the JVM’s Just-In-Time (JIT) compilation process. Applications are frequently scaled on CPU using the HPA. The CPU burst at start-up time can trigger the HPA to scale up the number of replicas unnecessarily, leading to resource waste and potential instability.
In this blog, you’ll see how to rightsize JVM applications running on Kubernetes and how to create a controlled scaling environment using the HPA with CPU utilization as the target scaling metric.
When a new JVM instance starts, it undergoes a JIT compilation phase, during which it analyzes and optimizes the application for improved performance. This process is CPU-intensive and can cause a temporary spike in CPU usage. To allow the CPU usage of the pod to burst, we avoid setting limits while we set the requests according to the long steady state CPU usage of the pod using recommendations generated by StormForge machine learning.
StormForge Optimize Live is a Kubernetes resource optimization and cost management platform. It analyzes applications and workloads using machine learning, and provides recommendations for setting optimal resource requests and limits based on actual usage patterns. By rightsizing your resources, StormForge helps you optimize resource utilization, reduce costs, and improve cluster stability.
resources:
requests:
cpu: "10m"
memory: "800Mi"If the HPA is configured to scale based on CPU utilization, it will detect the spike associated with the JIT compilation process at start-up time and assume that the application requires more resources. The HPA will then initiate the scaling process by creating additional pods or replicas. However, the new replicas also have CPU bursts much higher than the long term CPU usage at start-up time. The HPA will analyze the overall CPU utilization across all replicas and determine that the utilization is higher than the target utilization. This can cause the HPA to initiate another scaling event, creating even more replicas. This cycle can continue, with the HPA constantly scaling out to compensate for the perceived high CPU usage, only to find that the usage drops back down once the new replicas are online. This thrashing can lead to resource wastage, increased costs, and potential instability in the cluster.
You can visualize the thrashing by running kubectl apply -f controlled-scaling/jvm-app.yaml.
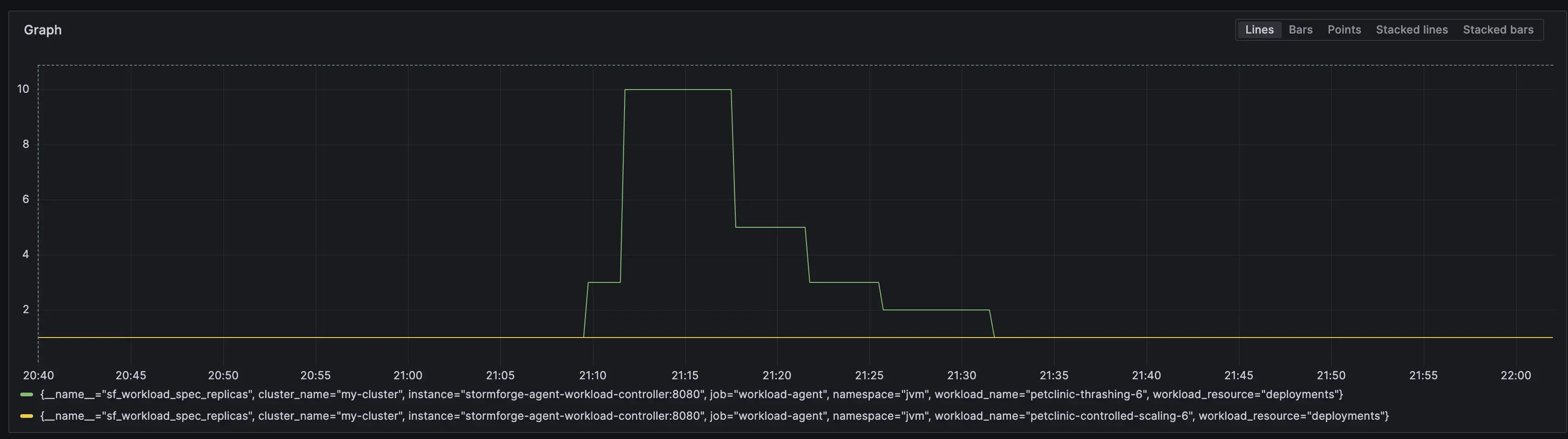
This deploys the pet clinic JVM application with a liveness probe. HPA is set to scale on CPU with a target utilization of 80% and max_replicas=10. This creates the thrashing in the figure below.
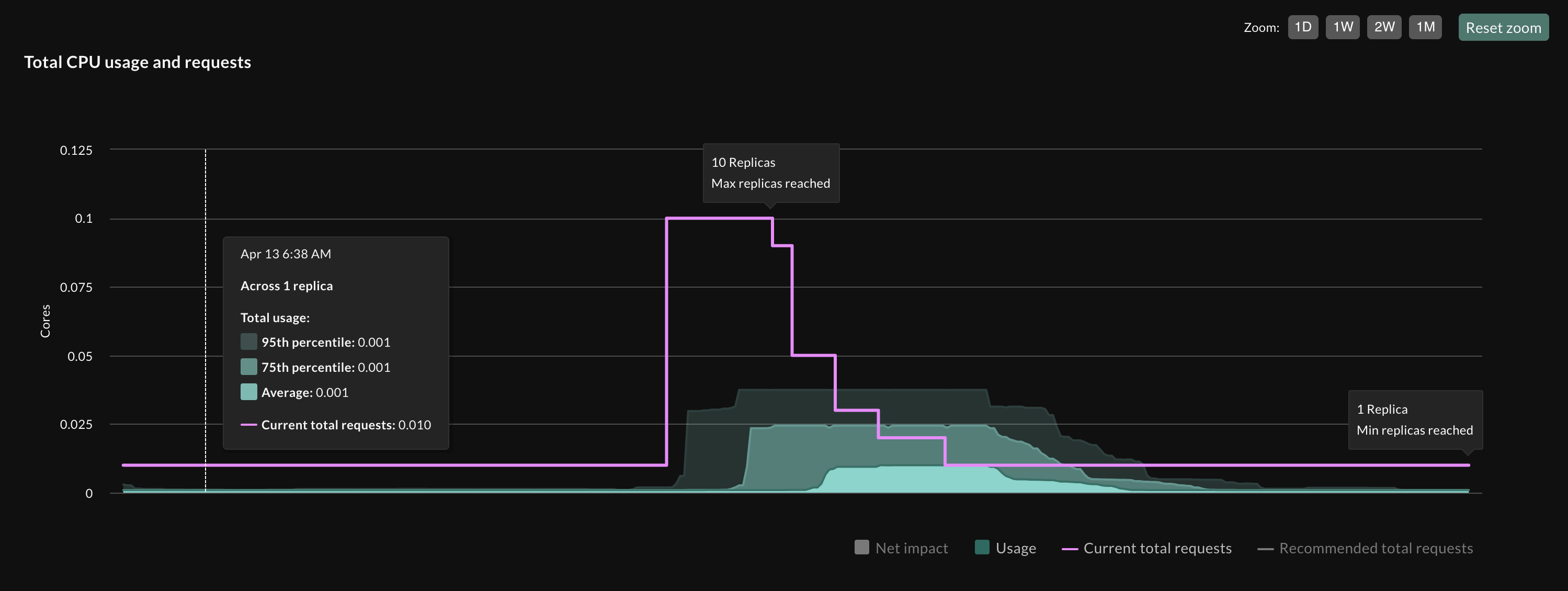
Each time a replica is added, the burst of CPU triggers a scale out event from the HPA. The number of replicas increases to max_replicas as defined by the HPA configuration. This issue is similar to the well-documented problem of HPA and Vertical Pod Autoscaler (VPA) thrashing when they scale on the same metric. In this scenario, the HPA scales out the number of replicas based on high CPU usage, while the VPA increases the CPU requests and limits for the pods. However, since both autoscalers are reacting to the same CPU usage metric, they can end up in a feedback loop, constantly scaling in opposite directions and causing cluster instability. Several blog posts and articles have discussed this issue already (e.g., this one).
Without a readiness probe configured, the HPA will use the CPU usage data, including the start-up burst caused by the JVM’s JIT compilation process. This can lead to the HPA continuously scaling out the number of replicas as it tries to compensate for the perceived high CPU usage by adding more instances.
To break this cycle, it’s essential to provide the HPA with accurate information about the application’s readiness state. By configuring a readiness probe with an appropriate initialDelaySeconds value, you can instruct Kubernetes to exclude containers from receiving traffic until they have completed the JIT compilation phase and are truly ready to handle requests. This prevents the HPA from reacting to the temporary CPU burst and avoiding unnecessary scaling events.
You can visualize a controlled scaling JVM application using kubectl apply -f controlled-scaling/jvm-app.yaml.
The initialDelaySeconds is set by looking at how long the initial CPU usage burst takes to decrease to its long term value.
readinessProbe:
httpGet:
path: /
port: 8080
scheme: HTTP
periodSeconds: 10
initialDelaySeconds: 180 # 3 minutes
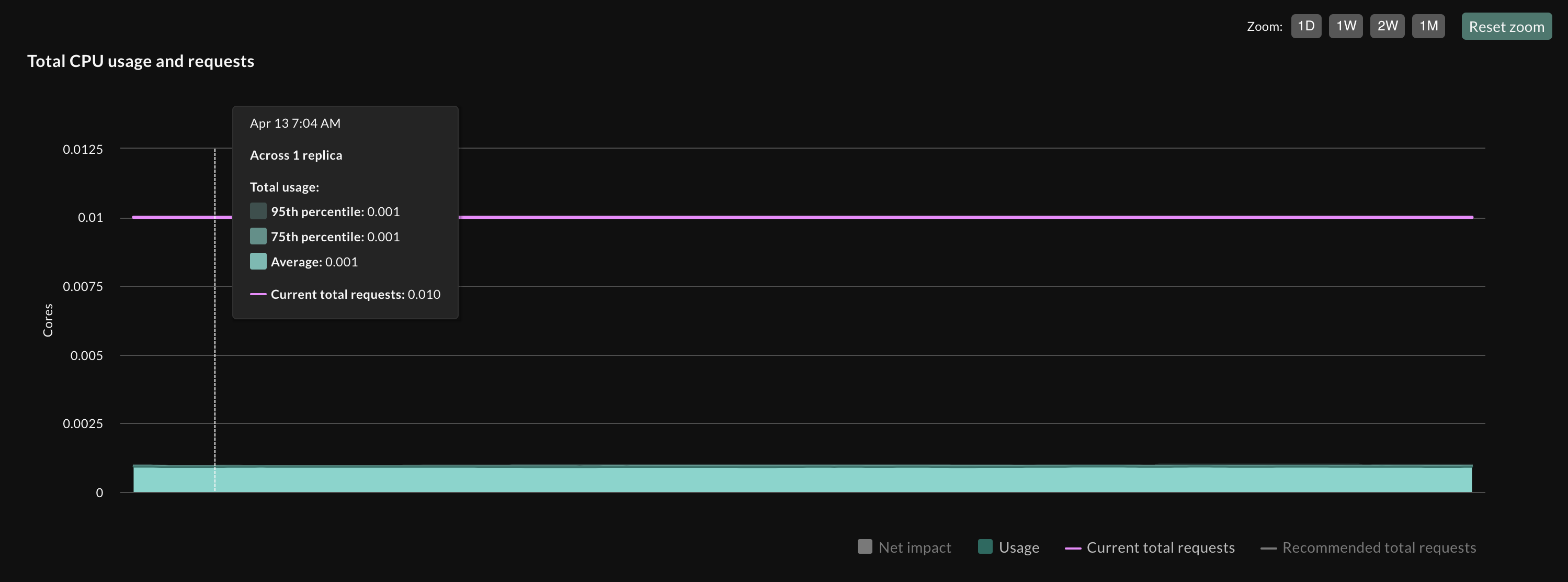
Setting up a properly configured readiness probe is the best way to mitigate this issue. The readiness probe allows you to instruct Kubernetes to exclude containers from receiving traffic until they are truly ready to handle requests. By setting an appropriate initialDelaySeconds value for the readiness probe, you can effectively instruct the HPA to ignore the CPU usage during the JVM’s start-up phase, preventing unnecessary scaling.
Alternatively, you could consider increasing the scaleUp: stabilizationWindowSeconds for the HPA, which would instruct the HPA to use a window-based approach for calculating metrics instead of the current metric value. This means that the HPA would only consider CPU utilization values within a specific time window, effectively ignoring the high CPU usage during start-up.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: petclinic-hpa-controlled-scaling-6
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: petclinic-controlled-scaling-6
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # default value
scaleUp:
stabilizationWindowSeconds: 180 # default value is 0A properly tuned readinessProbe offers a good solution for scaling JVM applications. The main challenge resides in selecting an appropriate initialDelaySeconds value. While this also potentially delays the scaling out process, reducing the HPA’s targetUtilization value provides a safeguard. StormForge provides recommendations for optimally rightsizing workloads alongside the HPA target utilization value. Note that the readiness probe used here checks the root path /. A more dedicated endpoint like /actuator/health/readiness would allow avoiding the initialDelaySeconds delay and provide a more accurate readiness check.
The scaleUp.stabilizationWindowSeconds HPA configuration stays in place during the lifetime of the deployment. If your application experiences periodic spikes in CPU usage that are shorter than the stabilization window, the HPA may not react in time, leading to potential performance issues or timeouts. Additionally, if multiple instances of your application start simultaneously, their combined CPU burst could still trigger the HPA to scale up, even with a longer scaleUp.stabilizationWindowSeconds. In such cases, the readiness probe would be a more reliable solution, ensuring that each instance is truly ready before being added to the service endpoints and considered for autoscaling decisions.
Scaling JVM applications on Kubernetes can be challenging due to the CPU burst during the JIT compilation process at start-up. This burst can cause the Horizontal Pod Autoscaler (HPA) to unnecessarily scale up replicas, leading to resource wastage and potential instability.
To mitigate this issue, the best approach is to configure a readiness probe with an appropriate initialDelaySeconds value. This instructs Kubernetes to exclude containers from receiving traffic until they have completed the JIT compilation phase and are truly ready to handle requests. By doing so, the HPA avoids reacting to the temporary CPU burst and prevents unnecessary scaling events.
While increasing the scaleUp.stabilizationWindowSeconds for the HPA can also help, it may not be as effective or responsive as using a well-configured readiness probe, especially for applications with periodic CPU spikes or multiple instances starting simultaneously.
By implementing a targeted solution like the readiness probe, along with rightsizing recommendations with a tool like StormForge, you can achieve controlled scaling of your JVM applications on Kubernetes, optimizing resource utilization and ensuring stable performance.
Remember, every application has unique characteristics and requirements, so it’s essential to monitor and adjust your scaling configurations accordingly. With the right strategies and tools, you can effectively manage the scaling challenges of JVM applications in Kubernetes environments.
We use cookies to provide you with a better website experience and to analyze the site traffic. Please read our "privacy policy" for more information.


