Blog
Scaling Up (or Down) Smartly with the Kubernetes Horizontal Pod Autoscaler
By Brad Ascar | Nov 05, 2020

Blog
By Brad Ascar | Nov 05, 2020
If you’ve been in a modern high-rise, you may have encountered a ‘smart elevator’. Like older elevators, they’re designed to move people up and down between floors, but that’s where the similarities end.
With smart elevators, there’s no pushing an Up or Down button, and no hoping that others won’t get on and turn your express ride into a local. Instead, you first go to a separate kiosk and select your desired floor. Then the smart elevator system directs you to the specific elevator that will get you there the fastest. The system is also efficient, combining your ride with others who have the same destination, minimizing the number of stops.
For your cloud-native technology stack, Kubernetes, with its Horizontal Pod Autoscaler (HPA) using default settings, is the traditional elevator in our analogy. It will get you where you want to go (scaling up or down) eventually.
What many people don’t realize, however, is that they already have smart elevator capabilities with their K8s/HPA resources. They just need to unlock those features with intelligent HPA tuning. With that tuning, you can automatically and rapidly scale up your K8s pods to meet increases in demand, and automatically spin them down when demand wanes.
With intelligent, automated, and more granular tuning, HPA helps Kubernetes to deliver on its key value promises, which include flexible, scalable, efficient and cost-effective provisioning.
There’s a catch, however. All that smart spin-up and spin-down requires Kubernetes HPA to be tuned properly, and that’s a tall order for mere mortals. If the tuning results in too-thin provisioning, performance can suffer and clusters can fail. If tuning results in over-provisioning, your cloud costs can go way up.
Let’s look more closely at Kubernetes HPA tuning challenges and how they can be solved. But first, some level-setting is appropriate.
The HPA is one of the scalability mechanisms built-in to Kubernetes. It’s a tool designed to help users manage the automated scaling of cluster resources in their deployments. Specifically, the HPA automatically scales up or down the number of pods in a replication controller, replica set, stateful set, or deployment.
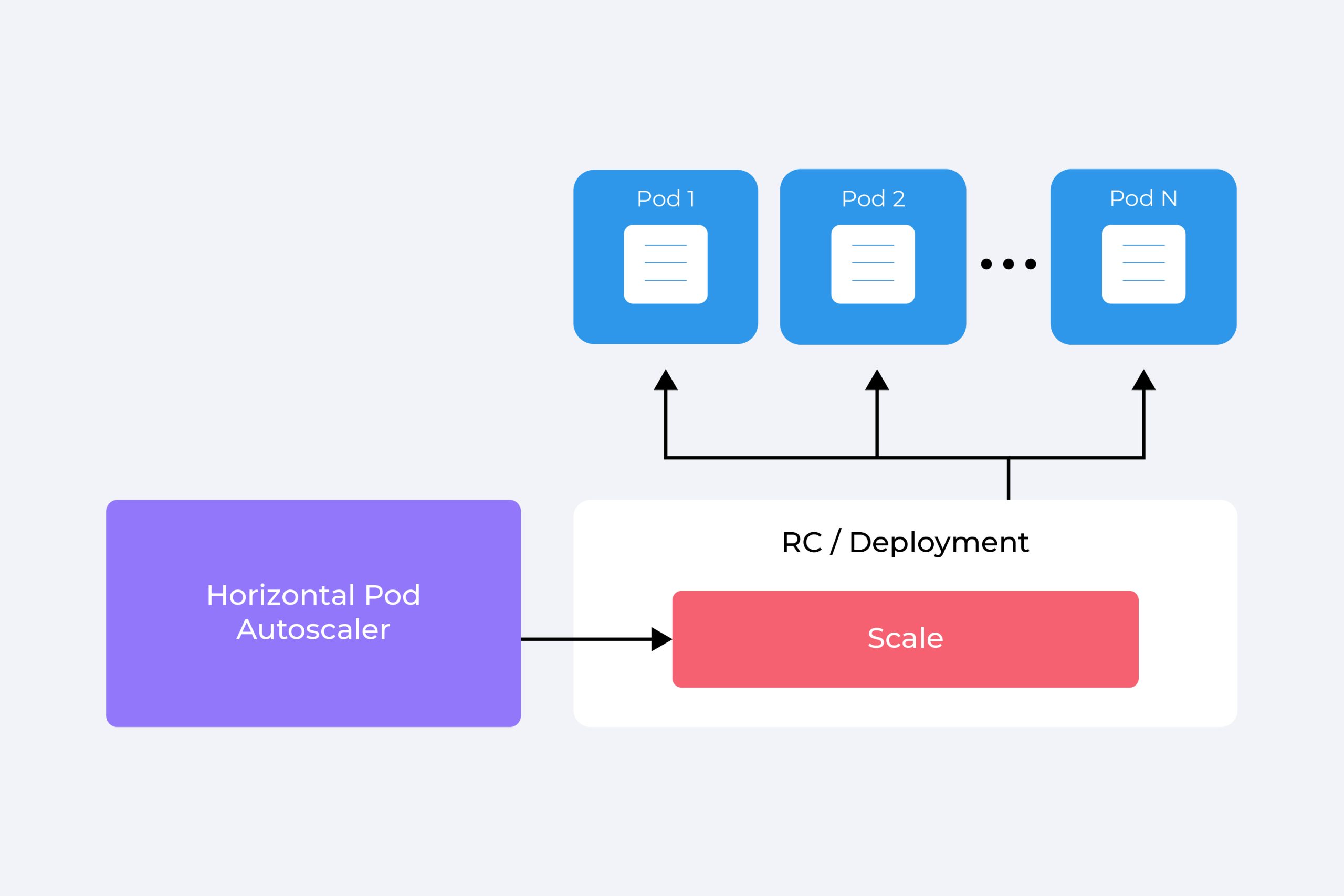
The HPA conducts its autoscaling based on metrics set by the user. A common choice of DevOps teams is to use CPU and memory utilization as the triggers to scale more or fewer pod replicas. However, HPA does allow users to scale their pods based on custom or external metrics.
Whatever metrics are chosen, the user sets the average utilization of all the replicas in a deployment, and then the HPA takes over. It handles adding or deleting replicas as needed to keep the utilization rates at the target values.
For teams that are early in their transitions to Kubernetes, it’s easy for them to take a “set it and forget it” approach with HPA. In many cases, they don’t even “set it”. They simply go with the ‘out-of-the-box’ HPA settings – the default target CPU utilization or memory utilization. For teams that want to do more with HPA, they can do that by using custom metrics, but that can quickly get complicated. Furthermore, for teams using a hosted K8s service, some of those customization options may not be available from their providers.
Applications are not created equal. To deliver exceptional user experiences, applications need to be fed with different types of resources at varying rates, and different times. Since the HPA’s default settings have a ‘one size fits all’ orientation, they’re certainly not optimal for individual applications and their specific workloads.
If the application is a web server for example, the speed at which the HPA adds replicas is critical in accommodating bursts in traffic. Without the ability to set a higher speed for replica additions for that specific app, the result would be slower scaling, which in turn, could negatively impact the user experience.
Without being able to change the policies for scaling up, the user is left with only a small number of values to work with, mainly a CPU utilization target and the number of maximum replicas. Work-arounds can be found, but they nearly always have drawbacks. With our web app, a simple fix would be to drop the CPU utilization target to a much lower value, like 20-25%. That way, slow-downs would be avoided because the HPA would be triggered early during an upswing in traffic. And there’s the drawback. With premature scaling, apps get overprovisioned, replicas get underutilized, and cloud costs increase significantly.
Only using a couple of settings, and only using their default values with HPA will not get you optimal performance, nor will it get you the highest cost-effectiveness across all the varied apps you’re transitioning to Kubernetes. Instead, you need your settings in HPA to reflect the nature (needs and wants) of the various apps.
CPU and memory isn’t the full picture of how an app behaves, however. They may stay flat or be very spiky, but not necessarily an indication of performance. Things like latency and throughput as much better signals for many apps. This is where the custom metrics come into play. Many times the real power comes in understanding the performance, not just the footprint of the application. Every app behaves differently, and therefore every HPA needs to be tuned to the app. One size certainly does not fit all, not even close.
But doing that is crazy-complicated. You need tests (experiments) that yield precise and actionable results. You also have to run the experiments continually because apps act/need differently as they run through their cycles, plus Day 1 stuff is different than Day 2 and Day N. You also need to run the experiments at high speeds (with automation), interpret the results – also at high speeds (w/automation), and lastly use automation to apply the recommendations –and this at high speeds (w/automation…are we seeing a trend here?)
StormForge Optimize Live does all of this. Teams can use it to support their HPA efforts to significantly improve what they have now, which is probably a hot mess.
With more intelligence and automation, smart elevators get you to your floor faster and more efficiently. It’s the same deal with HPA and app performance and reliability in Kubernetes – intelligent automation is clearly the way to go. Want a deeper dive into HPA tuning? Here’s a technical guide with a hands-on demo you can try. a blog by one of our engineers on the topic.
Try StormForge Optimize Live for FREE to start optimizing your Kubernetes environment now. Sign up for a free trial or play around in our sandbox environment.
We use cookies to provide you with a better website experience and to analyze the site traffic. Please read our "privacy policy" for more information.


