Chapter 10 - Kubectl Scale Deployment to 0
Scaling in Kubernetes refers to adjusting the number of pod replicas or modifying the resource allocations of pods to meet application demand, ensuring optimal performance, availability, and resource utilization in a cluster. Kubernetes supports both horizontal and vertical scaling: Horizontal scaling increases or decreases the number of pod replicas while vertical scaling adjusts the resource requests (CPU and memory) of existing pods.
In this article, you’ll learn how to use and apply the kubectl command with the scale subcommand to manually execute horizontal scaling. You’ll also see how and when to use kubectl to scale deployment to 0, which means reducing the number of running pods of an application or a workload to zero, and the limitations of this action. Additionally, you’ll learn how Kubernetes Event-Driven Autoscaling (KEDA) can fill in the gaps left by the Kubernetes Horizontal Pod Autoscaler (HPA). Finally, we highlight StormForge’s features for efficient horizontal and vertical scaling.
Summary of key concepts related to scaling kubectl deployment #
Using the kubectl scale command #
The kubectl command with the scale subcommand is used to scale the number of pods within a Kubernetes resource, such as a deployment or StatefulSet. Resources can be “scaled out,” which means increasing the number of replicas to handle the increased load, or “scaled in,” which means decreasing the number of replicas when the load decreases, allowing you to free up resources and reduce costs.
Here’s the general syntax for the kubectl scale command:
# sh
$ kubectl scale --replicas=<number_of_replicas> <resource_type>/<resource_name> <options>In this command:
- <number_of_replicas> is the new desired number of replicas.
- <resource_type> is the Kubernetes resource type, such as Deployment or StatefulSet.
- <options>: A number of options can be passed to filter the results.
Examples
Here are some specific examples showing the use of this command.
Scaling a deployment named nginx-deployment to 3 replicas:
# sh
$ kubectl scale --replicas=3 deployment/nginx-deploymentScaling all deployments in the current namespace with the label app=nginx to 2 replicas.
# sh
$ kubectl scale --replicas=2 deployment -l app=nginxScaling all deployments and stateful sets in the current namespace to 2 replicas:
# sh
$ kubectl scale statefulset,deployment --all --replicas=2Conditionally scaling the number of replicas of the mysql deployment to 3 if the value is currently 2:
# sh
$ kubectl scale --current-replicas=2 --replicas=3 deployment/mysqlNote that when the option --current-replicas is specified, it is validated before the scale is executed, and the precondition is guaranteed to hold true when the scale is sent to the Kubernetes API. This can prevent race conditions or unexpected changes during the scaling process.
Autonomous Rightsizing for Kubernetes Workloads

Automated vertical autoscaling designed to scale for 100K+ containers

Fully compatible with HPA functionality and cloud-based services

Powered by advanced machine learning with user-controlled guardrails
Scaling a Kubernetes deployment to 0 #
Scaling a Kubernetes resource such as a deployment or stateful set to zero involves setting the number of replicas for that resource to zero. This action instructs Kubernetes to terminate all pods associated with the specified resource.
Benefits of scaling to 0
Scaling to zero can offer significant benefits in a number of areas.
Cost savings
- Reduced resource usage: By scaling to zero, you no longer use the compute resources (such as CPU and memory) allocated to the application’s pods. This can lead to substantial cost savings, especially in cloud environments where you pay for resource usage.
- No idle resources: Scaling to 0 prevents resources from being wasted on idle applications. This is particularly useful for non-production environments like development or staging, where applications are not needed 24/7.
Maintenance
- Simplified updates: When an application is scaled to zero, it becomes easier to perform maintenance tasks, such as security patches or blue-green deployments. You can deploy another version of your running application and scale it up and down to check different scenarios without affecting live traffic.
- Dependency management: You can test to ensure the communication pathways between applications remain intact in case one of the applications is down by scaling each interdependent application to zero. If other applications continue working as expected, the communication pathways are intact. For instance, if the querying service is scaled down, ensure that other services do not rely on it for critical operations or handle its absence gracefully.
Testing
- Environmental cleanup: In testing scenarios, scaling to zero can be part of a cleanup process. After tests are completed, scaling down ensures that no residual resources are left running that could interfere with subsequent tests.
- Controlled startup: Scaling to zero allows for controlled startup sequences in testing environments. You can start specific services as needed in a known state, ensuring a clean slate for each test run.
Consequences for the application
Scaling a deployment to 0 has several direct consequences:
- Application unavailability: The most immediate effect is that the application will no longer be accessible. All running instances (pods) of the application will be terminated, so no new requests can be processed.
- Service disruption: Any ongoing sessions or connections will be immediately terminated. This could lead to a poor user experience if not managed carefully.
- Impact on state and data: For stateless applications, scaling to 0 is straightforward. However, for stateful applications, it’s important to ensure that the state is preserved, if necessary. This might involve persisting data to external storage before scaling down to avoid data loss.
The HPA limitation when scaling deployment to 0 #
The Horizontal Pod Autoscaler (HPA) automatically adjusts the number of replicas in a deployment, replica set, or stateful set based on observed and configured metrics. However, there is a limitation when it comes to scaling a Kubernetes deployment to zero.
Tha HPA usually operates based on metrics like CPU utilization or custom metrics from the running pods. When the deployment is scaled to zero replicas, there are no active pods to provide these metrics. As a result, the HPA cannot make decisions about scaling up from zero. This means that HPA requires a minimum of one replica to be running, so it cannot be used to completely shut down an application.
Let’s use an example, assuming that HPA is configured to scale the my-app deployment from 1 replica to 10. The kubectl scale command can be used to scale a deployment to zero, as shown below:
# sh
$ kubectl scale --replicas=0 deployment/my-appNow, no pods are running, and the HPA will no longer have metrics from running pods to monitor, so it cannot automatically scale the deployment back up. There should be a manual interaction to scale up to at least one pod, and then the HPA can scale the deployment based on the defined metrics and thresholds.
In the next section, you will learn about KEDA, one of the options that can be implemented to overcome this limitation.
Scaling down a deployment to 0 using KEDA #
Kubernetes Event-Driven Autoscaling (KEDA) extends the capabilities of the Horizontal Pod Autoscaler by providing significantly more flexibility, easy-to-use options for various metrics out of the box, and the important ability to scale applications to zero. KEDA introduces a custom Kubernetes resource, the ScaledObject, that defines how a particular deployment, stateful set, or other scalable resource should be dynamically scaled based on external event triggers or metrics.
The problem that KEDA solves
The HPA is normally used to scale based on a few built-in metrics (CPU and memory usage) or custom metrics from the Kubernetes Metrics Server. In contrast, KEDA makes it easier to scale workloads horizontally based on a wide range of external metrics and event sources, such as messages in a queue, database queries, HTTP requests, or any custom external metric from Azure Monitor, Prometheus, AWS CloudWatch, or Kafka.
KEDA natively supports scaling down to zero replicas when there are no events to process, which, as we’ve seen, is particularly useful for cost savings in environments with unsteady traffic loads. HPA doesn’t natively support scaling down to zero without custom workarounds.
Demo of scaling down a deployment to 0 using KEDA
This section will demonstrate how to scale down a Kubernetes deployment to zero using KEDA when a RabbitMQ queue is empty. Here are the prerequisites:
- Up and running Kubernetes cluster. You can use minikube or kind to run a Kubernetes cluster in your local environment.
- Kubectl installed to interact with Kubernetes.
- Helm installed to deploy Kubernetes workloads.
Step 1: Install KEDA
You can install KEDA using helm or kubectl, as shown below.
Using Helm:
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm repo update
$ helm install keda kedacore/keda --namespace keda --create-namespaceUsing kubectl:
$ kubectl apply -f https://github.com/kedacore/keda/releases/download/v2.4.0/keda-2.4.0.yamlIf needed, replace the version, in this case 2.4.0, with the one you are using.
You should be able to see KEDA pods running and ready within a few minutes:

Step 2: Install RabbitMQ on Kubernetes
Helm will be used to install RabbitMQ as below:
$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm install rabbitmq bitnami/rabbitmqThis will install RabbitMQ in your Kubernetes cluster with default settings, so the default user is “user" and the default cluster name is “rabbitmq.”
Step 3: Check RabbitMQ Installation Status
$ kubectl get pods -l app.kubernetes.io/name=rabbitmq
Usually, it takes a couple of minutes before the pod is running and ready.
Sample of RabbitMQ pod logs after successful installation:
Then you can retrieve the RabbitMQ password, through the below command:
$ export RABBITMQ_PASSWORD=$(kubectl get secret --namespace default rabbitmq -o jsonpath="{.data.rabbitmq-password}" | base64 --decode)This password will be used later when you login to RabbitMQ UI.
Step 4: Deploy a Worker/Consumer Application
Next, deploy an example worker application that consumes messages from RabbitMQ. Here's an example deployment that simulates a message-processing worker.
$ echo "
apiVersion: apps/v1
kind: Deployment
metadata:
name: rabbitmq-consumer
namespace: default
labels:
app: rabbitmq-consumer
spec:
selector:
matchLabels:
app: rabbitmq-consumer
template:
metadata:
labels:
app: rabbitmq-consumer
spec:
containers:
- name: rabbitmq-consumer
image: ghcr.io/kedacore/rabbitmq-client:v1.0
env:
- name: RABBITMQ_PASSWORD
valueFrom:
secretKeyRef:
name: rabbitmq
key: rabbitmq-password
imagePullPolicy: Always
command:
- receive
args:
- "amqp://user:${RABBITMQ_PASSWORD}@rabbitmq.default.svc.cluster.local:5672"
" | kubectl apply -f -
The RABBITMQ_PASSWORD will be retrieved from the “rabbitmq” secret deployed in the “default” namespace.
Step 5: Login to RabbitMQ Portal
Before moving to the next step, you can login to RabbitMQ portal using the username “user” and the password retrieved earlier. This will allow you to see the queue name created with the consumer as a default behavior.
You can do this using port-forward techniques in Kubernetes, as shown below:
$ kubectl port-forward pod/rabbitmq-0 15672:15672Then navigate through your browser to localhost:15672 and login with the username and password.
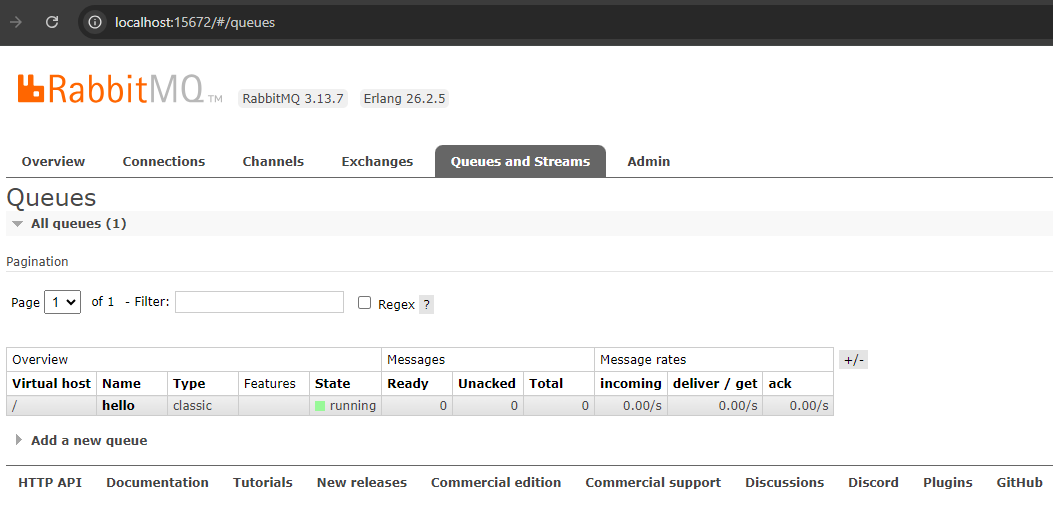
Below, you can see a queue named “hello” has been created and 0 messages are processed. This queue will be used to test the KEDA scaled object, as will be explained in the next steps.
Step 6: Configure KEDA to Autoscale Based on RabbitMQ Queue
Next, define and apply a KEDA ScaledObject to automatically scale the worker/consumer deployment based on the RabbitMQ queue length.
$ echo "
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-worker-scaledobject
spec:
scaleTargetRef:
name: rabbitmq-consumer
minReplicaCount: 0
maxReplicaCount: 5
triggers:
- type: rabbitmq
metadata:
host: "amqp://user:<RABBITMQ_PASSWORD>@rabbitmq.default.svc.cluster.local:5672"
queueName: "hello"
queueLength: '1'
" | kubectl apply -f -
You can use the proper configuration to reference RABBITMQ_PASSWORD variable, such as TriggerAuthentication object, which can be created and then referenced through the ScaledObject.
The above configuration will scale down rabbitmq-consumer deployment to 0 when there are 0 messages in the queue.
Step 7: RabbitMQ Consumer Status
As we don’t have messages in the queue, it is expected that rabbitmq-consumer deployment has been scaled down to 0. Let’s check that:
$ kubectl get deployment rabbitmq-consumer
So we don’t have any running instances of rabbitmq-consumer, as the queue is empty. This means that ScaledObject is working as expected.
In the next step, we will push a message to the queue to test the scaling-up scenario.
Step 8: Triggering the Scaling Up
In this step, we will add messages to the RabbitMQ queue to simulate load. KEDA should scale up rabbitmq-consumer as the RabbitMQ queue is not empty.
You can use the UI to push messages to the queue, click on the queue then “Publish message” section, write the message, and then publish it. Within a few seconds, you will notice a new rabbitmq-consumer pod is spinning up to consume the message.
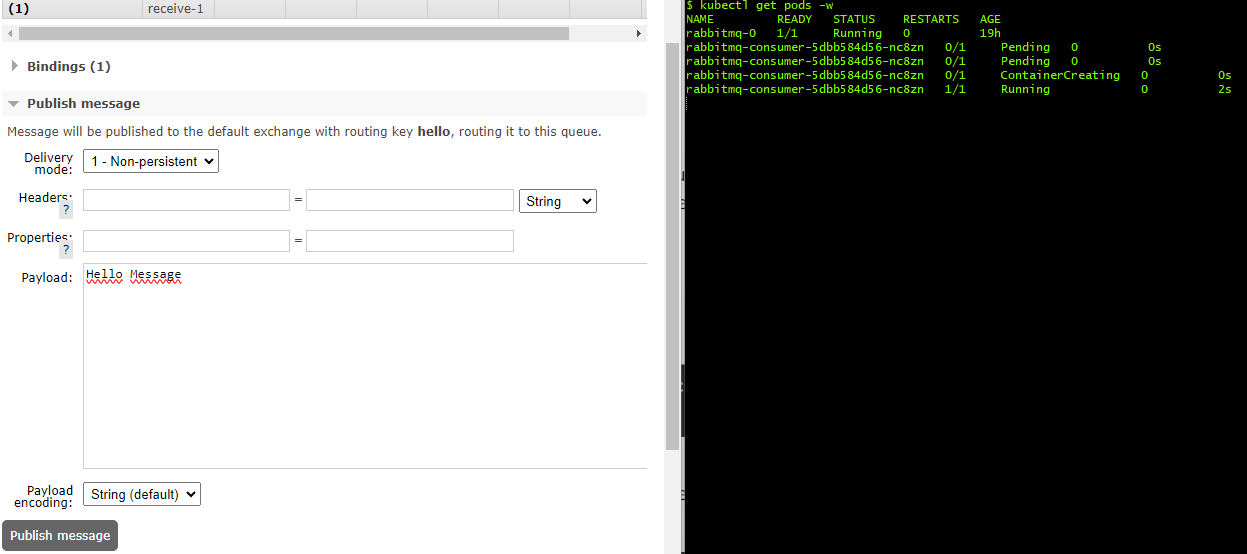
The rabbitmq-consumer deployment will be scaled down to 0 again when the queue is empty and after a cooldown period, which is 300 seconds as a default value.
Kubernetes resource management with StormForge #
While the HPA is powerful, it can sometimes lead to resource inefficiencies if it is not managed correctly. For instance, incorrectly set thresholds for metrics can cause the HPA to scale up or down either too aggressively or not aggressively enough. Also, If the pod is large, even a small increase in demand might cause a significant amount of unused capacity to be added. Additionally, limitations around scaling deployments to 0 leave waste on the table.
This is where StormForge Optimize Live comes into play. Optimize Live uses machine learning (ML) and automation to optimize application performance and resource utilization in Kubernetes environments. It detects trends in usage patterns to scale workloads down to near zero requests, minimizing waste while allowing workloads to respond to traffic. StormForge improves both horizontal and vertical scaling using ML-based resource recommendations and automated resource optimization.
ML-based recommendations
Optimize Live leverages machine learning to analyze your application’s resource usage patterns. It monitors scaling behavior and resource utilization to provide recommendations that can be applied for both the HPA target utilization and vertical rightsizing settings for CPU and Memory. These recommendations help you achieve the right balance between performance and cost, minimizing the risk of resource contention. Additionally, Optimize Live monitors resource utilization trends in the data to detect changes in patterns on the weekends or during the day, which it uses to forecast the correct resource needs for the next period.
You can read more about how machine learning is used to improve rightsizing recommendations in this blog.
Automated resource optimization
Optimize Live can automatically adjust resource requests and limits based on real-time data. Through dynamic resource adjustments, Optimize Live can optimize the performance of workloads and reduce resource waste by automatically applying recommendations via a patch to the Kubernetes API.
Alternatively, recommendations can be applied from the UI or via a GitOps workflow. When using Optimize Live’s Applier, users can set schedules to control how often recommendations get applied, thresholds for how large a recommendation needs to be compared to the previous, and control gates to slowly roll out larger recommendations.
You can read more about how Optimize Live works in this docs guide.
Conclusion #
While the kubectl command with the scale subcommand provides manual control over scaling Kubernetes resources, the HPA offers automated scaling. However, it is based on metrics and has limitations in scaling to zero. Kubernetes Event Driven Autoscaling (KEDA) addresses these limitations by enabling event-driven scaling, including scaling down to zero.
In this article, we’ve explored various methods to scale a Kubernetes application down to zero, highlighting how KEDA can bridge the gap left by the HPA. Additionally, we discussed how Optimize Live’s advanced optimization features can further enhance Kubernetes scaling by leveraging machine learning and automation for efficient resource utilization and performance optimization.
You can continue reading about advanced autoscaling in Kubernetes with KEDA and how Karpenter can be used to scale Kubernetes nodes.